It’s a feature that can be used with Exadata. Exadata is capable of offloading a large portion of a query’s workload to the storage cells.
So how it works?
Smart Scan is the capability of an Oracle Database to offload SQL processing to the Exadata Storage Servers. As with smart scan, database itself has less data to process once the storage servers process a large amount of data and return just a small portion to the database itself. Smart Scan works better with Data Warehouse/DSS databases than with OLTP databases.
For the Smart Scan to work, the SQL you run must have these requirements:
The segment you are querying must be stored in an Exadata Database Machine where the disk group with the cell.smart_scan_capable attribute is set to true.
A Full Table Scan or an Index Fast Full Scan operation must occur.
The segment must be big enough to fire a direct path read operation.
With all those three requirements met, there will be a Smart Scan operation.
Let us see this using the below.
With traditional, non-iDB aware storage, all database intelligence resides in the database software on the server. To illustrate how SQL processing is performed in this architecture an example of a table scan is shown below.
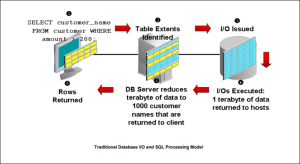
1)The client issues a SELECT statement with a predicate to filter and return only rows of interest. 2)The database kernel maps this request to the file and extents containing the table being scanned. 3)The database kernel issues the I/O to read the blocks. 4) All the blocks of the table being queried are read into memory. 5) Then SQL processing is done against the raw blocks searching for the rows that satisfy the predicate. 6) Lastly the rows are returned to the client.
As is often the case with the large queries, the predicate filters out most of the rows read. Yet all
the blocks from the table need to be read, transferred across the storage network and copied into
memory. Many more rows are read into memory than required to complete the requested SQL
operation. This generates a large number of data transfers which consume bandwidth and impact
application throughput and response time.
Integrating database functionality within the storage layer of the database stack allows queries,
and other database operations, to be executed much more efficiently. Implementing database
functionality as close to the hardware as possible, in the case of Exadata at the disk level, can
dramatically speed database operations and increase system throughput.
With Exadata storage, database operations are handled much more efficiently. Queries that
perform table scans can be processed within Exadata storage with only the required subset of
data returned to the database server. Row filtering, column filtering and some join processing
(among other functions) are performed within the Exadata storage cells. When this takes place
only the relevant and required data is returned to the database server.
In the figure below illustrates how a table scan operates with Exadata storage.
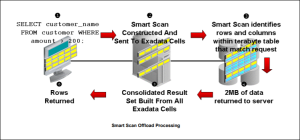
1) The client issues a SELECT statement with a predicate to filter and return only rows of interest. 2)The database kernel determines that Exadata storage is available and constructs an iDB command representing the SQL command issued and sends it the Exadata storage. 3)The CELLSRV component of the Exadata software scans the data blocks to identify those rows and columns that satisfy the SQL issued. 4) Only the rows satisfying the predicate and the requested Oracle White Paper— A Technical Overview of the Oracle Exadata Database Machine and Exadata Storage Server 23 columns are read into memory. 5) The database kernel consolidates the result sets from across the Exadata cells. 6) Lastly, the rows are returned to the client.
Smart scans are transparent to the application and no application or SQL changes are required. The SQL EXPLAIN PLAN shows when Exadata smart scan is used. Returned data is fully consistent and transactional and rigorously adheres to the Oracle Database consistent read functionality and behavior. If a cell dies during a smart scan, the uncompleted portions of the smart scan are transparently routed to another cell for completion. Smart scans properly handle the complex internal mechanisms of the Oracle Database including: uncommitted data and locked rows, chained rows, compressed tables, national language processing, date arithmetic, regular expression searches, materialized views and partitioned tables.
The Oracle Database and Exadata server cooperatively execute various SQL statements. Moving SQL processing off the database server frees server CPU cycles and eliminates a massive amount of bandwidth consumption which is then available to better service other requests. SQL operations run faster, and more of them can run concurrently because of less contention for the I/O bandwidth. We will now look at the various SQL operations that benefit from the use of Exadata.
Smart Scan Predicate Filtering
Exadata enables predicate filtering for table scans. Only the rows requested are returned to the database server rather than all rows in a table. For example, when the following SQL is issued only rows where the employees’ hire date is after the specified date are sent from Exadata to the database instance.
SELECT * FROM employee_table WHERE hire_date > ‘1-Jan-2003’;
This ability to return only relevant rows to the server will greatly improve database performance. This performance enhancement also applies as queries become more complicated, so the same benefits also apply to complex queries, including those with subqueries.
Smart Scan Column Filtering
Exadata provides column filtering, also called column projection, for table scans. Only the columns requested are returned to the database server rather than all columns in a table. For example, when the following SQL is issued, only the employee_name and employee_number columns are returned from Exadata to the database kernel.
SELECT employee_name, employee_number FROM employee_table;
For tables with many columns, or columns containing LOBs (Large Objects), the I/O bandwidth saved can be very large. When used together, predicate and column filtering dramatically improves performance and reduces I/O bandwidth consumption. In addition, column filtering also applies to indexes, allowing for even faster query performance.
Smart Scan Join Processing
Exadata performs joins between large tables and small lookup tables, a very common scenario for data warehouses with star schemas. This is implemented using Bloom Filters, which are a very efficient probabilistic method to determine whether a row is a member of the desired result set.
Smart Scan Processing of Encrypted Tablespaces and Columns
Smart Scan offload processing of Encrypted Tablespaces (TSE) and Encrypted Columns (TDE) is supported in Exadata storage. This enables increased performance when accessing the most confidential data in the enterprise.
Conclusion
The Smart Scan feature in Exadata enables SQL processing to happen at the storage tier, instead of the database tier, to improve query performance. Smart Scan reduces the volume of data sent to the database tier thereby reducing the CPU usage on database nodes.