Introduction:
APEX_DATA_PARSER is a feature in Oracle APEX (Application Express) that simplifies the process of uploading and parsing files in a web application.APEX_DATA_PARSER is a PL/SQL package provided by Oracle APEX to help developers parse and process the CSV files.
The following technologies has been used to achieve the same.
- Oracle APEX
- PL/SQL
Why we need to do:
Organizations often need to migrate data from legacy systems, and Oracle APEX makes this easier with tools like APEX_DATA_PARSER. Using this feature, users can upload CSV or other file formats containing legacy data and efficiently parse it into their APEX application’s database tables. This functionality also supports bulk data entry, where users can upload large datasets, such as customer lists or product inventories, significantly reducing the need for manual data entry. For example, employees can upload their expense reports in CSV or XLSX format, allowing the application to parse the files and update the financial database, simplifying expense tracking and reporting. Similarly, retailers and manufacturers can upload inventory files to update stock levels in their databases, ensuring accurate and real-time inventory management. This streamlines operations and improves overall data handling efficiency across various industries.
How do we solve:
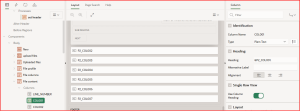
Step1: On a blank page,In an upload file region create a File page item for uploading files and add a button to submit the page.
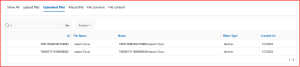
Step2: In an Uploaded files region We will then see a list of uploaded files for our active session, along with their profiles, columns, and data. This is all achieved with simple queries:
SELECT
f.id,
f.filename AS file_name,
f.name,
f.mime_type,
f.created_on
FROM apex_application_temp_files f
WHERE f.application_id = :APP_ID;
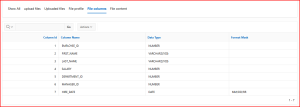
Step3: In the file profile, we can see details of the uploaded files, such as the name, MIME type, number of rows, and CSV delimiter.
File Profile query:
SELECT
f.name,
f.mime_type,
REGEXP_SUBSTR(f.name, ‘([^/]*)$’) AS file_name,
—
JSON_VALUE(f.profile_json, ‘$.”file-encoding”‘ RETURNING VARCHAR2) AS file_encoding,
JSON_VALUE(f.profile_json, ‘$.”csv-delimiter”‘ RETURNING VARCHAR2) AS csv_delimiter,
JSON_VALUE(f.profile_json, ‘$.”csv-enclosed”‘ RETURNING VARCHAR2) AS csv_enclosed,
JSON_VALUE(f.profile_json, ‘$.”headings-in-first-row”‘ RETURNING VARCHAR2) AS headings,
JSON_VALUE(f.profile_json, ‘$.”force-trim-whitespace”‘ RETURNING VARCHAR2) AS whitespace,
–JSON_VALUE(f.profile_json, ‘$.”columns”.size()’ RETURNING NUMBER) AS cols_,
JSON_VALUE(f.profile_json, ‘$.”parsed-rows”‘ RETURNING NUMBER) – 1 AS rows_
FROM (
SELECT
f.name,
f.mime_type,
APEX_DATA_PARSER.DISCOVER (
p_content => f.blob_content,
p_file_name => f.name,
p_max_rows => 100000
) AS profile_json
FROM apex_application_temp_files f
WHERE f.name = :P1_FILE
) f;
Step4: The File Columns region shows details like column name, data type, and format mask.code:
SELECT
column_position AS column_id,
REPLACE(column_name, ‘]’, ‘_’) AS column_name,
data_type,
REPLACE(format_mask, ‘”‘, ”) AS format_mask
FROM TABLE(APEX_DATA_PARSER.GET_COLUMNS((
SELECT
APEX_DATA_PARSER.DISCOVER (
p_content => f.blob_content,
p_file_name => f.name,
p_max_rows => 100000
) AS profile_json
FROM apex_application_temp_files f
WHERE f.name = :P1_FILE
)));
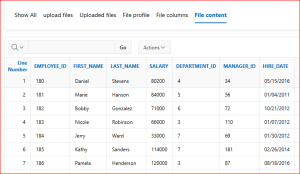
Step5:In the file content region, it shows the data of the columns.
Paste the following code :
SELECT
p.line_number – 1 AS line_number,
—
p.col001, p.col002, p.col003, p.col004, p.col005, p.col006, p.col007, p.col008, p.col009, p.col010,
p.col011, p.col012, p.col013, p.col014, p.col015, p.col016, p.col017, p.col018, p.col019, p.col020,
p.col021, p.col022, p.col023, p.col024, p.col025, p.col026, p.col027, p.col028, p.col029, p.col030
FROM apex_application_temp_files f
CROSS JOIN TABLE(APEX_DATA_PARSER.PARSE(
p_content => f.blob_content,
p_file_name => f.name,
p_skip_rows => 1
)) p
WHERE f.name = :P1_FILE;
Step6: I use page items and simple process to rename headers for the data columns. And Now, it’s time to decide how to handle the data: either store it in an APEX_COLLECTION or persist it in a real table.
Code :
FOR c IN (
SELECT
‘P1_COL’ || LPAD(column_position, 3, ‘0’) AS page_item,
REPLACE(column_name, ‘]’, ‘_’) AS column_name
FROM TABLE(APEX_DATA_PARSER.GET_COLUMNS((
SELECT
APEX_DATA_PARSER.DISCOVER (
p_content => f.blob_content,
p_file_name => f.name,
p_max_rows => 100000
) AS profile_json
FROM apex_application_temp_files f
WHERE f.name = :P1_FILE
)))
) LOOP
IF APEX_CUSTOM_AUTH.APPLICATION_PAGE_ITEM_EXISTS(c.page_item) THEN
APEX_UTIL.SET_SESSION_STATE(c.page_item, c.column_name);
END IF;
END LOOP;
Conclusion:
APEX_DATA_PARSER provides a powerful and flexible way to handle file uploads and parsing in Oracle APEX applications. By leveraging this feature, organizations can streamline data integration processes, improve data accuracy, and enhance overall operational efficiency across various domains.
Screenshots:
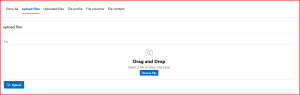
Screen Shot: 1 Upload files:
Screen Shot: 2 Uploaded files:
Screen Shot: 3 File profile:

Screen Shot: 4 File columns:
Screen Shot: 5 File content:
Screen Shot: 6 Rename Header: