1.Introduction
In OutSystems, handling document text extraction is not available as a built-in feature. Developers often need to process PDF, DOCX, and TXT files to extract text content for indexing, searching, or automation. Instead of manually integrating multiple libraries, we can build a reusable extension that provides this functionality efficiently.
This blog walks through the process of creating a FileTextExtractor component, which extracts text from PDFs, DOCX, and TXT files using a .NET-based OutSystems Extension and integrates it into an OutSystems Reactive Web App.
Additionally, this component can be highly useful for extracting text from invoice documents, allowing businesses to automate invoice processing, retrieve important details like invoice numbers, dates, and amounts, and integrate them into their workflow.
2.Why We Need This Solution?
Manually extracting text from files can be complex and time-consuming due to:
- Different encoding formats used in PDFs.
- Structured text storage in DOCX files.
- Need for a server-side solution to handle large file processing.
- Avoiding dependency on external API-based services.
A custom-built extension enables seamless text extraction directly within OutSystems, making it an efficient, scalable, and secure solution.
This approach is particularly beneficial for:
- Processing invoices automatically from PDF or DOCX files.
- Extracting text for search indexing or document classification.
- Improving data entry automation by eliminating manual text extraction.
3.How Do We Solve This?
To achieve text extraction from different file formats, we will create two applications:
- FileTextExtractor – A .NET C# Extension built using OutSystems Integration Studio for text extraction.
- FileTxtExtractor_DemoApp – A Reactive Web App that provides a user interface to test the extension.
Step 1: Create an OutSystems Extension
We’ll first create a .NET extension that contains C# logic to extract text from various document formats. This extension will be used in Service Studio to build a UI for text extraction.
1. Open Integration Studio
- Launch OutSystems Integration Studio.
- Create a new Extension Module and name it FileTextExtractor.
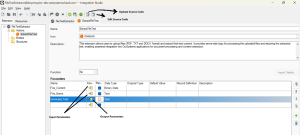
2. Define the Action & Parameters
- Inside the extension, create a new action and give it a meaningful name (e.g., ExtractFileText).
- Add two input parameters:
- File_Content (Binary Data) – The uploaded file’s content.
- File_Name (Text) – The uploaded file’s name (including extension).
- Add one output parameter:
- Extracted_Text (Text) – The extracted text from the file.
- Mark the input parameters as mandatory (required fields).
3.Add C# code for Text Extraction
- Click on the C# Code Editor button in Integration Studio. This will open Visual Studio, automatically creating a project with the defined parameters.
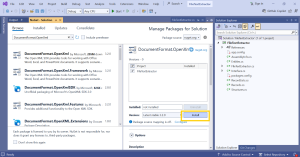
4. Install Required NuGet Packages
To handle different file formats, install the following .NET libraries:
- iText7 → For extracting text from PDF files.
- DocumentFormat.OpenXml → For extracting text from DOCX files.
- System.IO → For handling TXT files.
To install these:
- Right-click on the Solution Explorer in Visual Studio.
- Select Manage NuGet Packages.
- Search for the above libraries and install the latest versions.
5. Implement the C# Logic
- Write the logic within FileTextExtractor.cs
- Reads the file’s binary content.
- Determines the file type (PDF, DOCX, TXT) using its extension.
- Uses appropriate libraries to extract text.
Find the source code below:
using OutSystems.HubEdition.RuntimePlatform;
using OutSystems.RuntimePublic.Db;
using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
using DocumentFormat.OpenXml.Packaging;
using DocumentFormat.OpenXml.Wordprocessing;
namespace OutSystems.NssFileTextExtractor {
public class CssFileTextExtractor : IssFileTextExtractor {
public void MssExtractFileText(byte[] ssFile_Content, string ssFile_Name, out string ssExtracted_Text) {
ssExtracted_Text = string.Empty;
try
{
// Define the temporary file path
string tempPath = Path.Combine(Path.GetTempPath(), ssFile_Name);
// Save the file data temporarily
File.WriteAllBytes(tempPath, ssFile_Content);
// Extract content based on the file extension
ssExtracted_Text = ExtractFileContent(tempPath);
// Clean up the temporary file
if (File.Exists(tempPath))
{
File.Delete(tempPath);
}
}
catch (Exception ex)
{
ssExtracted_Text = $”Error processing file: {ex.Message}”;
}
}
/// Extracts the content of the file based on its type (PDF, DOCX, or TXT).
private string ExtractFileContent(string filePath)
{
string fileExtension = Path.GetExtension(filePath).ToLower();
switch (fileExtension)
{
case “.pdf”:
return ExtractTextFromPDF(filePath);
case “.docx”:
return ExtractTextFromDOCX(filePath);
case “.txt”:
return File.ReadAllText(filePath);
default:
return “Unsupported file type.”;
}
}
/// Extracts text from a PDF file using iText 7.
private string ExtractTextFromPDF(string pdfFilePath)
{
string extractedText = string.Empty;
try
{
using (PdfReader reader = new PdfReader(pdfFilePath))
{
using (PdfDocument pdfDoc = new PdfDocument(reader))
{
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
var page = pdfDoc.GetPage(i);
extractedText += PdfTextExtractor.GetTextFromPage(page);
}
}
}
}
catch (Exception ex)
{
extractedText = $”Error extracting text from PDF: {ex.Message}”;
}
return extractedText;
}
/// Extracts text from a DOCX file using Open XML SDK.
private string ExtractTextFromDOCX(string docxFilePath)
{
string extractedText = string.Empty;
try
{
using (WordprocessingDocument wordDoc = WordprocessingDocument.Open(docxFilePath, false))
{
Body body = wordDoc.MainDocumentPart.Document.Body;
extractedText = body.InnerText;
}
}
catch (Exception ex)
{
extractedText = $”Error extracting text from DOCX: {ex.Message}”;
}
return extractedText;
}
}
}
6. Publish the Extension
- Once the code is implemented and saved, go back to Integration Studio.
- Click 1-Click Publish to compile and deploy the extension to OutSystems.
Step 2: Create a Reactive Web App to Use the Extension
Now that we have created the FileTextExtractor extension, we need to build a Reactive Web App to use it.
1. Create a New Reactive Web Application
- Open OutSystems Service Studio.
- Create a new Reactive Web Application and name it FileTxtExtractor_DemoApp.
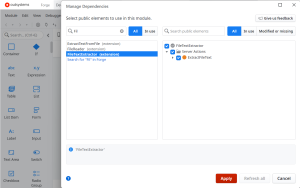
2. Add the Extension as a Dependency
- Click on Module → Manage Dependencies.
- Search for FileTextExtractor (the extension we created in Integration Studio).
- Select all available actions and click Apply.
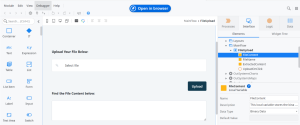
3.Build the User Interface (UI)
Now, we will design a UI to allow users to upload a file and extract its text.
- Add a File Upload Widget → To allow users to upload a document.
- Add a Button → Label it “Extract Text” to trigger extraction.
- Add a Text Area → To display the extracted text.
The UI should look something like this:
4.Implement the Logic
- Use an OnChange event → When a user selects a file, store it in a variable.
- Call the ExtractFileText action (from the extension) when the button is clicked.
- Pass the uploaded file’s binary content and name to ExtractFileText.
- Display the extracted text in the Text Area.
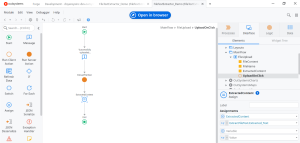
Click on Publish after all the steps are done.
Step 3: Test and Validate
To ensure the application works as expected, follow these testing steps:
Test with Different File Formats → Upload PDF, DOCX, and TXT files and verify the extracted text.
Check Error Handling → Try uploading unsupported file formats and verify proper error messages.
Test with Real-World Invoice Documents → Ensure correct text extraction from invoice PDFs and other structured documents.
Example:
I tried testing the below sample invoice pdf downloaded from the internet
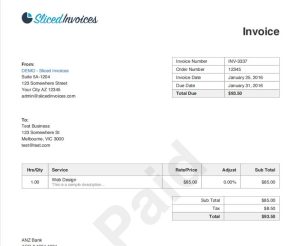
Below is the output from the FileTextExtractor app we created and results produced for the above tested invoice.
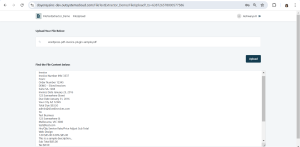
4.Conclusion
By following these steps, we successfully created a FileTextExtractor extension and integrated it into an OutSystems Reactive Web App. This reusable component simplifies document processing, allowing seamless text extraction for various use cases like searching, indexing, and automation.
Next Steps:
- Improve error handling for complex document structures.
- Extend support for additional formats like CSV or RTF.