Introduction
In relational databases like Microsoft SQL Server, handling comma-separated values (CSV) in a single column can be challenging, especially when it comes to removing duplicates. This task often arises when datasets contain redundant entries in such lists, which can lead to data integrity issues and inefficiencies in processing. The SQL code provided demonstrates an effective approach to remove duplicate values from CSV strings.
The following technology has been used to achieve the expected output.
- MS SQL
Why we need to do
1.Data Quality:
Redundant entries can reduce the reliability of the data. Removing duplicates ensures accurate and clean datasets.
2.Performance:
Queries that process smaller, non-redundant datasets execute faster.
3.Readability:
Cleaned and deduplicated data is easier to interpret and analyse.
4.System Requirements:
Some systems or applications may require unique values for processing, making deduplication a necessity.
How do we solve:
The SQL code solves the problem of duplicate removal using the following steps:
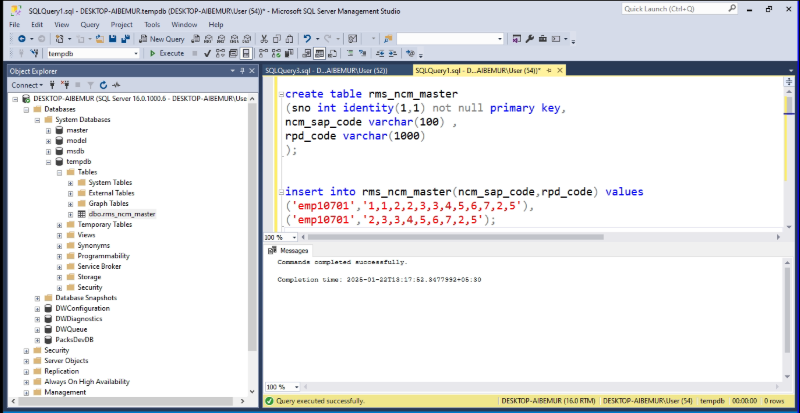
Step 1: Create the Table and Insert Sample Data
We start by creating a table (rms_ncm_master) to hold the comma-separated values and then insert sample data for testing:
CREATE TABLE rms_ncm_master (
sno INT IDENTITY(1,1) NOT NULL PRIMARY KEY,
ncm_sap_code VARCHAR(100),
rpd_code VARCHAR(1000)
);
INSERT INTO rms_ncm_master(ncm_sap_code, rpd_code) VALUES
(’emp10701′, ‘1,1,2,2,3,3,4,5,6,7,2,5’),
(’emp10701′, ‘2,3,3,4,5,6,7,2,5’);
SELECT * FROM rms_ncm_master;
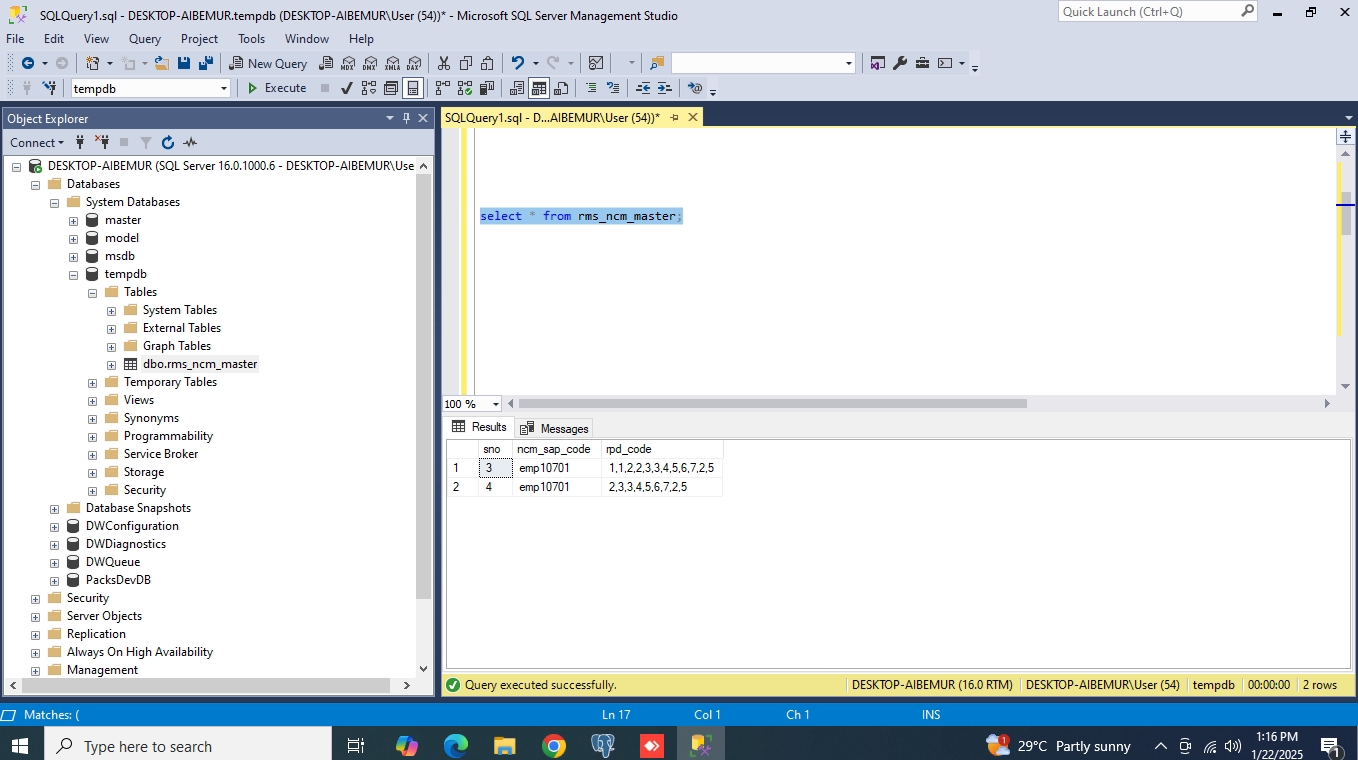
Step 2: Split, Deduplicate, and Reconstruct the CSV
This SQL code removes duplicates and reconstructs the cleaned CSV for each ncm_sap_code:
SELECT ncm_sap_code,
STUFF (
(SELECT
‘,’ + CONVERT(VARCHAR(MAX), rpd_code)
FROM (
SELECT
SUBSTRING(rpd_code, 1, CHARINDEX(‘-‘, rpd_code) – 1) AS ncm_sap_code,
CONVERT(INT, SUBSTRING(rpd_code, CHARINDEX(‘-‘, rpd_code) + 1, LEN(rpd_code))) AS rpd_code
FROM (
SELECT DISTINCT ncm_sap_code + ‘-‘ + rpd_code AS rpd_code
FROM (
SELECT ncm_sap_code,
LTRIM(RTRIM(m.n.value(‘.[1]’, ‘varchar(max)’))) AS rpd_code
FROM (
SELECT ncm_sap_code,
CAST(‘<XMLRoot><RowData>’
+ REPLACE(CONVERT(VARCHAR(MAX), rpd_code), ‘,’, ‘</RowData><RowData>’)
+ ‘</RowData></XMLRoot>’ AS XML) AS x
FROM rms_ncm_master
) t
CROSS APPLY x.nodes(‘/XMLRoot/RowData’) m(n)
) t
) t1
) y
WHERE y.ncm_sap_code = z.ncm_sap_code
ORDER BY ncm_sap_code, rpd_code
FOR XML PATH(”)
), 1, 1, ”
) AS rpd_code
FROM (
SELECT
SUBSTRING(rpd_code, 1, CHARINDEX(‘-‘, rpd_code) – 1) AS ncm_sap_code,
CONVERT(INT, SUBSTRING(rpd_code, CHARINDEX(‘-‘, rpd_code) + 1, LEN(rpd_code))) AS rpd_code
FROM (
SELECT DISTINCT ncm_sap_code + ‘-‘ + rpd_code AS rpd_code
FROM (
SELECT ncm_sap_code,
LTRIM(RTRIM(m.n.value(‘.[1]’, ‘varchar(max)’))) AS rpd_code
FROM (
SELECT ncm_sap_code,
CAST(‘<XMLRoot><RowData>’
+ REPLACE(CONVERT(VARCHAR(MAX), rpd_code), ‘,’, ‘</RowData><RowData>’)
+ ‘</RowData></XMLRoot>’ AS XML) AS x
FROM rms_ncm_master
) t
CROSS APPLY x.nodes(‘/XMLRoot/RowData’) m(n)
) t
) t1
) z
GROUP BY ncm_sap_code;
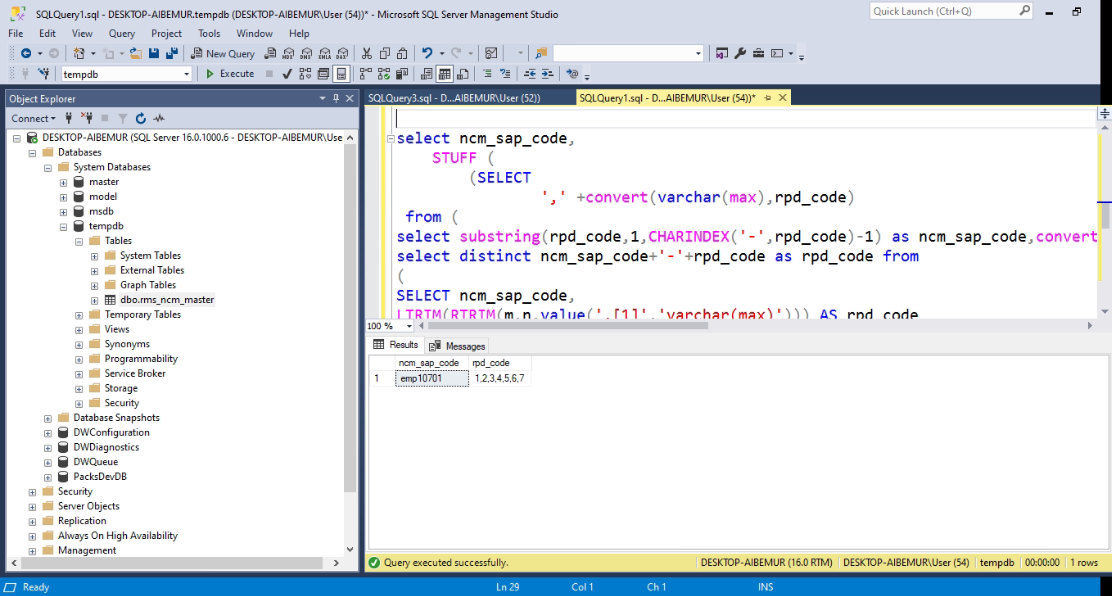
Conclusion:
The provided SQL solution effectively addresses the challenge of removing duplicate values from comma-separated lists in a SQL Server table. By leveraging XML parsing, the query splits the CSV strings into individual values, removes duplicates using the DISTINCT keyword, and reconstructs the cleaned values into a deduplicated CSV string.
This approach ensures:
- Data Integrity: The dataset is cleaned of redundant entries, improving its reliability for analysis and reporting.
- Scalability: The method is efficient and adaptable for large datasets with complex CSV structures.
- Performance: Deduplication and grouping streamline data processing, enabling faster and more accurate results.