Introduction/ Issue:
Working with large PDF documents can be challenging when you need to extract specific information quickly. Manually searching through multiple pages is time-consuming and prone to human error. The challenge is to create an AI-powered system that can understand the context of a document and answer questions in natural language — without the user having to read the entire file.
Why we need to do / Cause of the issue:
PDF files are widely used for storing reports, manuals, legal documents, and research papers. However:
- Manual Search is Inefficient: Scrolling through hundreds of pages is slow.
- No Built-in Q&A: Standard PDF readers don’t provide an AI-based feature to ask questions and get direct answers.
- Complex Content: Technical PDFs often contain a mix of text, tables, and images, making extraction harder.
- Impact: Time wasted in manual searching leads to reduced productivity and possible oversight of critical information.
By using Artificial Intelligence (AI), we can:
- Convert the document into a machine-understandable format.
- Use AI embeddings and large language models (LLMs) to understand context.
- Provide accurate answers instantly, even for complex queries.
How do we solve:
We can build a Python-based AI application using Streamlit, LangChain, FAISS, and Google Generative AI to:
- Upload and Read PDFs – Extract text using PyPDF2.
- Chunk Text for Processing – Break down the extracted text into smaller, AI-processable segments.
- Create AI Embeddings – Convert text chunks into vector embeddings using GoogleGenerativeAIEmbeddings.
- Store and Search with FAISS – Store embeddings in FAISS and retrieve relevant chunks using AI similarity search.
- Question Answering with AI – Use a LangChain conversational chain with the Gemini AI model to understand context and provide precise answers.
Steps :
1. Importing Required Libraries
We use Streamlit for the UI, PyPDF2 to read PDFs, LangChain for AI orchestration, Google Generative AI for embeddings and Q&A, and FAISS for fast vector search.
import os, io
from langchain_community.vectorstores import FAISS
from langchain_google_genai import GoogleGenerativeAIEmbeddings, ChatGoogleGenerativeAI
from langchain.chains.question_answering import load_qa_chain
from langchain.prompts import PromptTemplate
from dotenv import load_dotenv
import google.generativeai as genai
2. Loading API Key and Configuring Environment
The following code snippet loads the .env file, retrieves the GOOGLE_API_KEY, and configures the Google Generative AI client if the key is found.
load_dotenv() api_key = os.getenv(“GOOGLE_API_KEY”)
if api_key:
genai.configure(api_key=api_key)
To set this up, create a .env file and store your API key as shown below:
3. Setting Up the Streamlit UI
We create a simple web interface where users can upload PDFs and ask questions.
st.title(“📄 Chat with your PDF using Gemini”)
4. Setting Up Cached Embeddings and Chat Models
This section defines cached functions for loading the embeddings model and the chat model. By using @st.cache_resource, the models are initialized only once and reused in subsequent runs, reducing load time and improving performance. The embeddings model is set to “models/embedding-001”, while the chat model uses “gemini-1.5-flash-latest” with a temperature of 0.3 for balanced, consistent responses.
@st.cache_resource
def get_embeddings():
return GoogleGenerativeAIEmbeddings(model=“models/embedding-001”)
@st.cache_resource
def get_chat_model():
return ChatGoogleGenerativeAI(model=“gemini-1.5-flash-latest”, temperature=0.3)
5. Extracting Text from PDFs
We read the uploaded PDFs and extract text from each page.
def get_pdf_text(pdf_files): text = “” for uploaded_file in pdf_files:
reader = PdfReader(io.BytesIO(uploaded_file.read()))
for page in reader.pages:
text += page.extract_text() or “”
return text
6. Splitting Text into Chunks
We split large documents into smaller, overlapping chunks so the AI can process them better.
def get_text_chunks(text, chunk_size=1000, chunk_overlap=200):
splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
return splitter.split_text(text)
7. Creating a Vector Store
We store text embeddings in FAISS for fast semantic search.
def get_vector_store(text_chunks, persist_path=“faiss_index”):
embeddings = get_embeddings()
vectorstore = FAISS.from_texts(texts=text_chunks, embedding=embeddings)
vectorstore.save_local(persist_path)
return vectorstore
8. Building the Q&A Chain
We define a prompt template and load an the model that can answer questions from retrieved chunks.
def get_conversational_chain():
prompt_template = “””
Answer the question using the context below.
If not found, say “Answer not found in the context.”
Context: {context}
Question: {question}
Answer:
“””
model = get_chat_model()
prompt = PromptTemplate(template=prompt_template, input_variables=[“context”, “question”])
return load_qa_chain(model, chain_type=“stuff”, prompt=prompt)
9. Processing User Queries
We search relevant chunks using FAISS, pass them to the AI model, and display the answer.
def user_input(user_question, persist_path=“faiss_index”): embeddings = get_embeddings()
new_db = FAISS.load_local(persist_path, embeddings, allow_dangerous_deserialization=True)
docs = new_db.similarity_search(user_question, k=4)
chain = get_conversational_chain()
response = chain({“input_documents”: docs, “question”: user_question}, return_only_outputs=True)
st.write(“### 🤖 Answer:”)
st.write(response.get(“output_text”, “No output found.”))
10. Uploading PDFs & Asking Questions
We allow users to upload PDFs, process them into embeddings, and then type in their questions.
with st.sidebar: pdf_docs = st.file_uploader(“Upload PDF(s)”, accept_multiple_files=True) if st.button(“Submit & Process”):
raw_text = get_pdf_text(pdf_docs)
text_chunks = get_text_chunks(raw_text)
get_vector_store(text_chunks)
st.success(“Vector store created successfully!”)
user_question = st.text_input(“Ask a question about your PDFs:”)
if user_question:
user_input(user_question)
11. Run the App and test it out!
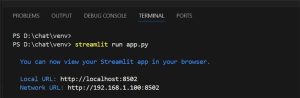
Run the Streamlit app using your file name, which will generate a localhost URL (as shown below). Open this URL in your browser to access the application’s UI.
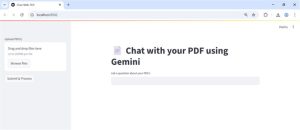
You’ll see your app interface as shown below. Simply upload a PDF, then click Submit & Process to generate vector embeddings.
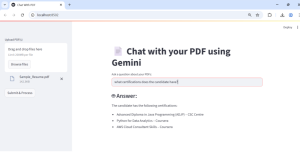
Once the success message appears on the sidebar, simply type your question in the input box and press Enter. The system will instantly process your query using vector embeddings and the Gemini model, delivering accurate answers directly from your document.
Conclusion:
This AI-powered document question-answering system combines Streamlit for UI, LangChain for LLM orchestration, Google Generative AI for embeddings and question answering, and FAISS for efficient vector search. It enables natural language interaction with your documents, saving hours of manual reading and boosting productivity. This solution is especially valuable for professionals dealing with large, information-dense PDFs — enabling faster, smarter, and AI-assisted decision-making.