What Is an Execution Plan?
When you send a query to the database, it’s the job of the SQL optimizer to figure out how to execute it, and that process creates the query’s execution plan. The plan is the driving directions for your query.
For example, join table 1 to table 2 and then join table 3.
By looking at the route the database took, you can see if it chose the fastest path or if you can make a faster one by building a shortcut.
Here is the execution plan for a two-table join:
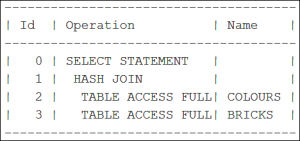
Each line in the plan is a separate operation. These operations are linked via a parent/child relationship.
The plan is a tree. The SELECT statement at the top is the root, the tables are the leaves at the bottom, and in between you’ll find a whole host of possible operations.
These fall into three categories:
- Single-child operations
- Multichild operations
- Joins
As the name suggests, a single-child operation always has exactly one operation below it in the execution plan tree. Common examples of this are grouping and sorting steps.
Multichild operations, which can have one or more operations below them, are rare. The most likely one you’ll see is a UNION (ALL) operation.
And that just leaves joins, which always have exactly two children. Each of these children may themselves be joins, tables, or any other plan operation.
How to Read an Execution Plan
In a text-based execution plan, the indentation indicates the parent/child relationship. The parent of each step is the first line above it, indented to the left. An operation’s children are those below it, indented to the right, up to the next operation at the same depth.
You could also draw the plan above to look like the image below.

To follow an execution plan, the database uses a depth-first search, which starts from the top of the plan and works down the tree to the first leaf. It then walks back up the tree to the first operation with an unvisited child.
The search then repeats the process, walking down the tree to the next leaf. From there it walks back up the tree to the next operation with an unvisited child. And this repeats until the search has read all the steps in the execution plan.
So the order of operations for the execution plan for the two-table join above is
-
Start from the top (SELECT STATEMENT) and go down the tree to the first leaf. This is the TABLE ACCESS FULL of the COLOURS table.
-
Pass the rows from this table up to the first leaf’s parent, the HASH JOIN.
-
Look for the next unvisited child of step 1. This is the TABLE ACCESS FULL of the BRICKS table.
-
Pass the rows from this table up to its parent, the HASH JOIN.
-
All the children of step 1 have been accessed, so pass the rows that survive the join to the SELECT STATEMENT and back to the client.
Note that the data flows up the plan, from the leaves to the root.
Here’s another execution plan example. This one includes a four-table join:

Here the order of operations is
-
Again, start from the top of the plan (SELECT STATEMENT) and go down to the first leaf. This is the TABLE ACCESS FULL of the COLOURS table in execution plan step 4.
-
Pass the rows from this table up to the first leaf’s parent, which is the HASH JOIN in step 3.
-
Find the next unvisited child, which is the TABLE ACCESS FULL of the TOYS table in step 5.
-
Pass the rows to the HASH JOIN in step 3. Step 3 has no more children, so return the rows that survive the HASH JOIN in step 3 to the HASH JOIN in step 2.
-
Search for the next child of step 2. This is the TABLE ACCESS FULL of the PENS table in step 6.
-
Pass these rows to the HASH JOIN in step 2. Step 2 has no more children, so return the rows that survive the HASH JOIN in step 2 to the HASH JOIN in step 1.
-
Repeat the process until you’ve run all the operations. So the complete order for accessing the execution plan step IDs is: 4, 3, 5, 3, 2, 6, 2, 1, 7, 1, and 0.
The arrows in below image shows this order, starting with the SELECT STATEMENT going to the full-table scan of the COLOURS table:

More advanced examples and ways to interpret them can be found here